I did some exploration a couple weeks ago re: concurrency in Python, with totally blogworthy results!
We often use the phrase 'waiting on IO' to describe 'cases when threads should improve efficiency of a single core'.
The most common scenario in modern web programming is probably waiting on HTTP responses or database queries, both of which play well with Python threading to improve scheduling / waste less time.
Here's some light test code we can use to check this out:
def get_content(url):
print('starting read')
r = requests.get(url)
print('done reading')
return r.content
def factorial(n, ix):
print('factorial {ix} starting'.format(ix=ix))
val = reduce(lambda a, b: a * b, range(1, n, 1))
print('factorial {ix} done'.format(ix=ix))
return val
def threadtest():
io_thread = threading.Thread(target=get_content, args=(URL, ))
cpu_thread = threading.Thread(target=factorial, args=(FAC, 1))
io_thread.start()
cpu_thread.start()
io_thread.join()
cpu_thread.join()
def synctest():
get_content(URL)
factorial(FAC, 1)
if __name__ == '__main__':
from timeit import Timer
synctimer = Timer("synctest()", "from __main__ import synctest; gc.enable()")
synctimer_times = synctimer.repeat(10, 1)
threadtimer = Timer("threadtest()", "from __main__ import threadtest; gc.enable()")
threadtimer_times = threadtimer.repeat(10, 1)
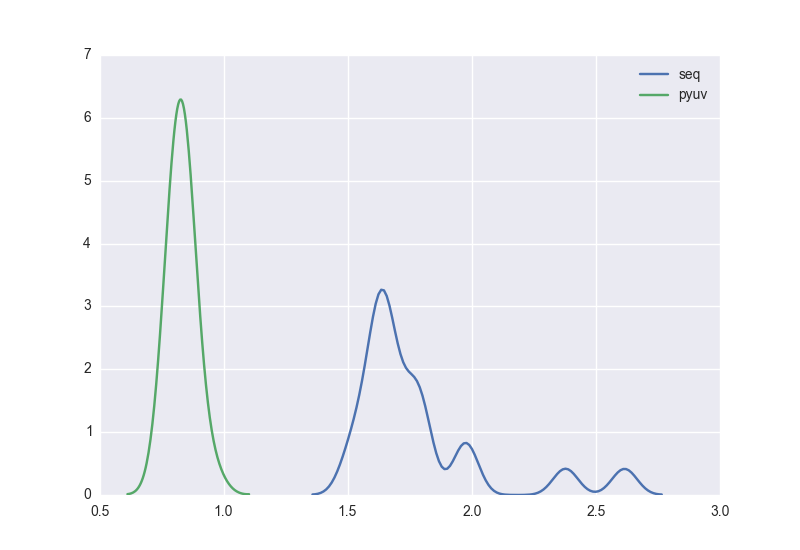
And here're the results:
As you can see, the threaded version successfully does the factorial while it is waiting for a web response.
But does this work for IO from disk?
To test, we can just swap in a new function and point the script at a relatively big file on disk:
def count_lines(fn):
print('starting read')
open(fn, 'r').read()
print('done reading')
return
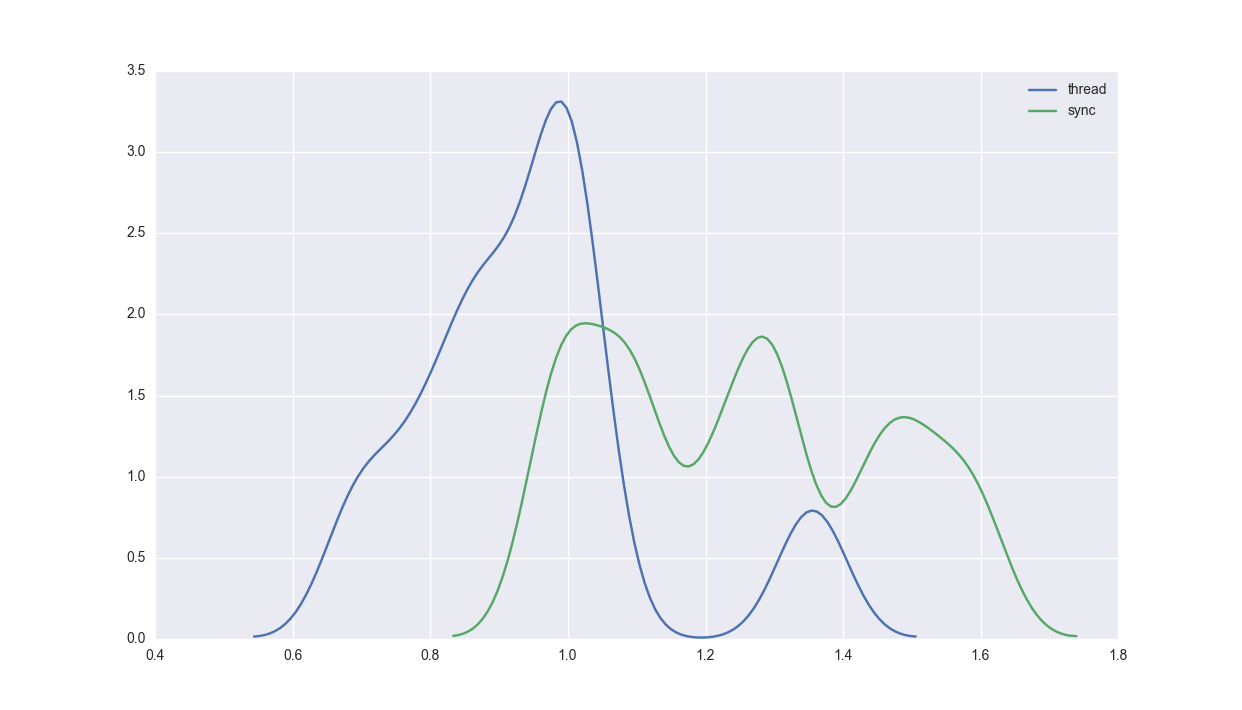
And as before, the results via seaborn density plots:
Not really much of a gain!
So: can you actually parallelize the disk IO and compute tasks via threads in Python? Without spawning more processes?
This smells like a potential issue with Python's GIL, or 'global interpreter lock'.
The GIL basically says there's only one entry point to the CPython interpreter, and if you (a Python thread) are passing instructions in, you will retain that status at the front of the line until you release it (or, if you're not holding it explicitly, 100 instructions go by).
So while waiting on a socket to have new content (the way we do for web and database requests) lets other threads proceed, perhaps disk IO doesn't work so nicely!
At this point we should maybe slow down and say: what is disk IO, anyway? Fundamentally, I understand it to be a call to your operating system's kernel that says 'read these bytes from the file at this location to the memory buffer at this other location'. In our 'read speed rules of thumb' scale, we think of this as being 'spinning magnet' speed, which is much slower than memory or CPU speed. Thus, we should be able to tell the kernel to copy that information and do some computing while it deals with the spinning disk. (An added thorn is that the OS may cache a file in memory after reading it, so we may be ultimately just copying memory from location to location, and ultimately waiting on the disk only for the first call.)
Now, the complexity for how we do this in Python is another issue. We need the system call to be made in a way that would allow some other Python code to run while the reading is happening. That is, we need whatever's going on when you call read on a file object to 'release the GIL'.
It's not clear that really happens. Here's the bottom of the rabbit hole, the read function in cpython's iomodule's fileutil.c:
/* Read count bytes from fd into buf.
On success, return the number of read bytes, it can be lower than count.
If the current file offset is at or past the end of file, no bytes are read,
and read() returns zero.
On error, raise an exception, set errno and return -1.
When interrupted by a signal (read() fails with EINTR), retry the syscall.
If the Python signal handler raises an exception, the function returns -1
(the syscall is not retried).
Release the GIL to call read(). The caller must hold the GIL. */
Py_ssize_t
_Py_read(int fd, void *buf, size_t count)
{
Py_ssize_t n;
int err;
int async_err = 0;
#ifdef WITH_THREAD
assert(PyGILState_Check());
#endif
Typically, this read method is called in a while loop until a file is exhausted. The caller, then, is a while loop (by the name of readall) that calls the code above again and again. Entering the function, there's an assertion that the GIL is being held. So it looks like there's no way to do other Python work while the system call is being handled!
Fortunately, there are other ways of reading a file than this iomodule. In particular, various C libraries for event loop programming are accessible to us, which may offer their own explicitly non-blocking interface to file system calls.
One such library is libuv, the micro event library that backs nodejs. Among many other things, it allows you register file system work (such as opening and reading) on an event loop, and to pass callbacks that should receive the return value of that work.
For the final tests, we'll look at the performance comparison among threaded/synchronous/callback approaches. To address the potential 'cached file' problem, we'll delete and create a bunch of files as part of each trial run. And to make the motivation a bit realer, we'll now consider the task of reading a directory of files and calculationg the md5 checksum of each file.
More code and results are on the repo here, but to cut to the chase, the callback-based strategy dominated the synchronous one, while the threaded performance remained in that vague "this might be better" territory!