In the last post, we saw that our strategy of online updates and performance-based alternative rendering efficiently put our best alternative in front of "users".
Now we will begin approaching the practical problems in using a system like this.
In the last implementation, our current estimates of alternative performance were used to synchronously determine the alternative the user should see next. In a web-scale setting, this is a problem: we want to have a variable number of workers serving content, and we want them to respond very fast (no SciPy in the web server!). We also may want to avoid re-initializing the SciPy object of a Beta distribution with every impression, as this is the most expensive operation we have so far. (Yes, this could be solved by simply using the Beta distribution's probability density function directly.)
To that end, I've sketched an implementation with two separate Actors for our two separate concerns -- impression serving and distribution updating.
A primary question is: what is the minimum communication required between these services, and what data structures can represent that?
Impression serving wants quick access to the asset it should serve next.
Distribution updating wants quick access to the latest click-through outcomes.
We can accomplish this with a stack and some labeled counters:
First, the counters:
Then, the stack:
Both of these data structures are available in Redis, which can be clustered for high availability and is easily available as a managed service in AWS.
For the moment, we'll just show that this scheme works by using globals in a single Python process. Relevant snippets to be pulled out below, but here's the full sketch.
Rather than simulate the situation on a timeline, we can just alternate between impression and update tasks at a certain rate. I give the impression worker a bit of state so it can keep track of when it should switch back over to the updater:
self.mean_requests_per_batch = 300
self.batch_index = 0
self.batch_size_dist = poisson(self.mean_requests_per_batch)
self.batch_target = self.batch_size_dist.rvs(1)[0]
Alternating between tasks in a single Python process is accomplished with gevent. Our Actors will simply yield control at the end of each task and will take an action if they have something in their inbox.
The impression worker handles tasks with a function like:
def receive(self, message):
cta_idx = self.stack.pop()
# "serve" the ad
outcome = is_clicked(cta_idx)
outcome_event = (cta_idx, True if outcome else False)
# theoretically done by another service
OUTCOMES[outcome_event] += 1
self.batch_index += 1
if self.batch_index == self.batch_target:
update.inbox.put('stop')
self.batch_target = self.batch_size_dist.rvs(1)[0]
self.batch_index = 0
gevent.sleep(0)
else:
view.inbox.put('go')
gevent.sleep(0)
Interactions with the shared data structures - counter increments and stack pops - are conflict free, so this role can be played by many simultaneous services.
The update worker is a bit more complicated.
First, here it is without any optimizations:
def receive(self, message):
for idx in range(len(self.dists)):
self.dists[idx] = beta(
OUTCOMES[(idx, True)],
OUTCOMES[(idx, False)])
vals = np.vstack([dist.rvs(self.batch_size) for dist in self.dists])
self.stack += [vals[:, i].argmax() for i in range(len(vals[0, :]))]
view.inbox.put('render')
gevent.sleep(0)
We re-initialize all distributions and add a predetermined number of draws to the stack.
My sketch adds two quick optimizations:
The first is dead simple, but the second requires some decisions. It's a bit like the concept of 'capital requirements': The bank (ie, stack) should have enough elements to prevent a 'run on the bank'.
Rather than use the number of popped elements in recent batches to estimate the distribution of traffic volume, I'll take a simpler / more paranoid approach.
# how much was popped since last update?
just_consumed = self.target_size - len(self.stack)
# we want batch size to be twice the largest consumption we've seen
# obviously, over time we'll see more and more outliers and raise this higher and higher, but that's okay
self.batch_size = max(self.batch_size, (just_consumed * 2))
# here's the "capital requirement": determine the size of an additional reservoir beyond what's pushed each batch
# as a guard against steeply increasing traffic volume
self.target_size = max(self.target_size, (self.batch_size * 2))
# since we intend to push far more entries than we're likely to pop
# we should remove old entries to keep the stack length stable
# (if we're pushing to reach a new, larger target size, we may not need this)
to_trim = max((len(self.stack) + self.batch_size) - self.target_size, 0)
# draw new entries and push them
vals = np.vstack([dist.rvs(self.batch_size) for dist in self.dists])
for i in range(self.batch_size):
self.stack.append(vals[:, i].argmax())
# trim entries from the old side
for i in range(to_trim):
self.stack.popleft()
# this is only exactly true in the non-concurrent example,
# but it is always true net of impressions served during update process
assert len(self.stack) == self.target_size
As usual, a GIF of the beta distributions during training:
Each of the 100 frames here corresponds to an 'update' batch running. After about 30 batches, the distributions are pretty well stabilized.
And how about batch size? Suppose we're expecting ~300 requests per batch -- how long of a stack are we maintaining, and how many are being pushed each update?
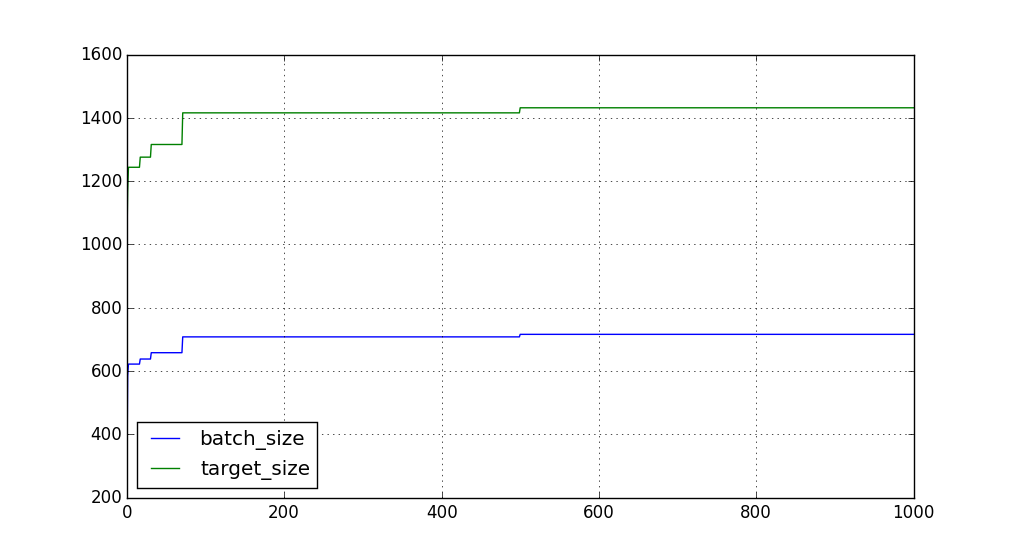
Our initial settings were too low, so we see this quickly get pushed to a pretty stable size. Eventually, we see a high outlier and raise the ceiling one more time.
This sketch shows a scalable way to implement online A/B testing with relatively little volume / performance knowledge up front.
